導論
我們提出一種基於漢字結構的學習方法。這套結構長期以來未被正確或系統地理解。我們的框架概述如下。
1. 漢字是語義組合系統
每個漢字要麼是原子,要麼是複合字。複合字的意義來自其部件的語義的組合。
1.1 原子字
原子字是象形符號,不能再分割成更小的表意部件,如日、木、水。
1.2 複合字
複合字由俗稱部首的部件組成。部首分三類:
在我們的框架中,物旁和視旁統稱為形旁。
不同類型的部首可以靈活組合,例如:
- 物 + 物:休 = 亻 + 木 = 人 + 樹 = 人靠在樹旁 = 休息
- 物 + 元:根 = 木 + 艮 = 樹 + 邊緣 = 樹的邊緣
- 視 + 物:家 = 宀 + 豕 = 房屋 + 豬 = 內有豬的房屋 = 家
- 元 + 元:辱 = 辰 + 寸 = 跨越邊界 + 界(人為界定的範圍) = 越禮失分、出其界限 = 恥
- 視 + 元 + 元 = 冠 = 冖 + 元 + 寸 = 覆蓋 + 初 + 界(人為界定的範圍) = 以一個覆蓋物,將「初始狀態」放入一個人定的範圍 = 標示成人的帽子,後引申為居首
形旁的含義早已為人熟知,但元旁的含義長期未被系統理解。我們框架的主要貢獻在於系統地解碼了元旁的含義。
我們認為,學習主要部首(特別是元旁)的含義,以及它們如何組合,是學習常用漢字乃至中文詞彙的高效途徑。
2. 漢字是帶標籤的圖解
漢字書寫系統不只是象形圖畫,而是帶標籤的圖解。每個圖解的構件有三類:具體事物(物旁)、視覺構件(視旁)和標籤(元旁),可靈活組合。
例如,富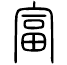 由視覺構件宀(房屋)和標籤滿(畐)組成,構成「滿屋」的圖解——即富裕:
由視覺構件宀(房屋)和標籤滿(畐)組成,構成「滿屋」的圖解——即富裕:
又如,根由木(樹)和標籤邊緣(艮)組成,構成「樹的邊緣」的圖解——即根:
根的等價圖解
再如,冠由視覺構件冖(覆蓋物)和兩個標籤初(元)、界(人為界定的範圍)(寸)組成,構成圖解表示「將初置入界(人為界定的範圍)的覆蓋物」——即表示成年的帽子,標誌孩童進入社會規範:
冠的等價圖解
漢字這種帶標籤的圖解——物旁、視旁和元旁的組合——具有豐富的表達力,能夠表示無限多的概念。
3. 大多數漢字記錄了核心概念的投射
3.1 語義輻射
早期漢語每個詞是一個音節,由一個漢字表示。大量早期漢語詞彙通過將表達核心概念的詞投射到多個具體領域而形成,產生一種放射狀的派生結構,我們稱之為語義輻射。而漢字記錄了這些語義投射。例如:
3.2 多級投射
語義投射可以多級進行,產生包含複合元旁的漢字。例如:
3.3 元旁可預測讀音
這種通過投射造詞的過程使元旁能夠預測包含它的漢字的讀音。例如,艮的讀音與根、跟、齦、垠、恨、墾相近。這是因為根、跟、齦、垠、恨、墾是從艮這個詞通過投射派生出來的。然而,艮的讀音只是接近,而不能精确刻画這些派生詞的讀音。
一个元旁不一定在所有包含它的字中都能预测其读音, 但不論预测读音與否它的含義保持穩定:
- 如果一個字含有兩個元旁,那麼至少一個元旁不能預測其讀音。比如寸預測村的读音,而冠的读音由元预测,而非由寸预测,说明冠这个词由元这个词投射而来。但是寸的含義不論其是否預測發音都保持穩定。
- 在辱中,元旁辰和寸都不預測讀音,但它們的含義穩定。
- 這與形旁不預測發音但含義保持穩定是一致的。
3.4 語義輻射是跨語言的普遍現象
通過輻射核心概念詞造詞並非漢語獨有,而是各語言的共同機制。例如英語:
- 詞根whole(原始印歐語:*kailo,意為完整)投射到身體領域產生hale(健壯)、heal(治癒)、health(健康),投射到精神領域產生holy(神聖)。
- 詞根mark(原始印歐語:*merg,意為邊界)投射到空間領域產生margin(邊緣),投射到人物領域產生marquis(邊境守護者→貴族)。
- 詞根*weid(看見)投射到認知領域產生wit(智慧)、wise(明智),投射到人物領域產生wizard(智者→巫師)、witness(見證者)。
3.5 漢字與字母代表不同的設計取捨
字母書寫系統在記錄上述語義投射時是有損的。投射域是隱含的,因為它們沒有編碼在發音中。漢字能夠顯式記錄這些領域投射,因為它不要求書寫形式與發音強綁定——表示域的部首,如根中的木,或者冠的冖和寸在漢字中不發音。
另一方面,漢字只能近似記錄語音,而字母能更精確地記錄語音。
漢字優先記錄語義而非語音。字母書寫系統優先記錄語音而非語義。